Jenkins is one of the favorite tools for orchestrating deployment and releases tasks, along with Bamboo from Atlassian. Jenkins begun its story in Sun Microsystem back in 2005 at java.net as Hudson project. Its aim is to easily build the code written by programmers and integrate their works with revision control (SCM). Bamboo is also a nice tool to coordinate release and deployment and they both are based on the Continuous Integration premises of bulding multiple integration on a daily basis.
Even though it does help setup and coordinate some of the automated tasks related to Continuous Integration, it does not embrace entirely the Continuous Delivery vision to use the pull mechanism (customer driven) instead of push mechanism. Due to its nature as Continuous Integration tools, Jenkins is task driven, not flow driven.
Continuous Integration (CI) is a predecessor to Continuous Delivery (CD). The basic principle of CI is simple: “members of a team integrate their works frequently, at least once a day.” The CI method will enable multiple integrations per day at every commit. That is the reason why Jenkins, with its CI philosophy is task driven, because it imposes the frequent update from team members.
Continuous Delivery, on the other hand is an extension of Continuous Integration. Started in 2010, the idea of CD is to move forward and focusing on customers need. Therefore the release in Continuous Delivery is driven by customers, rather than driven by developers like Continuous Integration. When we speak of lean software development in its true form, CD provides the lean environment and continuous improvement.
Continuous Delivery, on the other hand is an extension of Continuous Integration. Started in 2010, the idea of CD is to move forward and focusing on customers need. Therefore the release in Continuous Delivery is driven by customers, rather than driven by developers like Continuous Integration. When we speak of lean software development in its true form, CD provides the lean environment and continuous improvement.
Today, we have seen some new tools are coming to the market. Let me make a guess at how the next CD tool will look like:
- Provide a visual representation of the delivery pipeline
- Look sexy.
- System Environment aware
- Cloud and virtualization aware
- Handle manual decisions and manual triggers
- Consolidate reports and link them to the right release
- Configuration management aware.
- Open-Source.
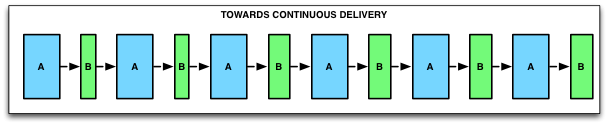
VISUAL REPRESENTATION OF THE DELIVERY PIPELINE
The next generation CD tool must be able to represent the entire Delivery Pipeline: all the way from commit, integration testing stages, up to production.
.png)
(visual above from Nhan Ngo)
It will have to represent the different stages of the pipelines, and the tasks being run in each stage.
Jenkins does have a plugin for that. But like everything else with Jenkins, it looks rather ugly and is badly integrated with the other plugins.
LOOK SEXY.
The next generation CD tool must look awesome, no excuses!
It needs to appeal to business analysts, product managers, project managers, testers alike, not only to developers.
It needs to appeal to business analysts, product managers, project managers, testers alike, not only to developers.
SYSTEM ENVIRONMENT AWARE
Jenkins only knows about slaves. But an environment is rarely comprising of only one server.
A good CD tool must understand the concept of the division between production and development environment and allow one to define on which node of the environment the task should run. Here is how an environment might look like:
A good CD tool must understand the concept of the division between production and development environment and allow one to define on which node of the environment the task should run. Here is how an environment might look like:

On top of this, the tool should be able to scale up and down the number of environments, depending on how much code change is pushed through the SCM.
In other words: more environments when the developers are making a lot of changes, less environments when they are sleeping (hopefully at night).
I envision this as maintening a pool of environments:
- when there is less commits happening, decomission the environments (and the servers)
- when there is more commits happening, comission new servers from templates and setup the environment
- make sure there is enough environments warmed up and ready to be used (i.e. 5 in standby, max 20 running at the same time)
- allow one to define the roles of the servers in the environments and what task can be run in each server
Those environments will be used mostly for integration and automated testing: regression testing, functional testing, performance testing and so forth
CLOUD AND VIRTUALIZATION AWARE
From the paragraph above you can deduct that the environment will need a Cloud platform. Otherwise at least it needs virtualized resources available on demand.
The CD tool needs to be able to communicate with the Cloud provider's API, in order to commission and decommission servers.
HANDLE MANUAL DECISIONS
Jenkins does not have a concept of manual decision. In a way it makes sense. It's a tool for automation only.
However, Jenkins’ automation of all tasks leads to miscommunication. It is difficult to answer the question of how to track where the location of the build is in the delivery? And whether it has passed the manual gates: decisions, manual testing, exploratory testing, and demo?
The next CD tool must visually assist decision-making and provide full complete history of build-test-release.
CONSOLIDATE REPORTS
The next generation CD tool will be able to consolidate everything and every bits and pieces of information about a release
- functional tests reports
- performance tests reports
- code coverage
- commit history
- change log
- etc
Unfortunately, Jenkins does a poor job with that. One has to dig into every single job in order to know everything that has happened to a build.
BE CONFIGURATION MANAGEMENT AWARE
Tools like Puppet and Chef have come to the market, but unfortunately they don't play well with Jenkins. We must integrate the CD tool to the one that manage the infrastructure, environments and servers.
Wouldn't it be nice if it could understand Chef Recipes and Puppet Manifests ?
What if you could create a new environment from Puppet recipe, and injecting it into your Delivery Pipeline.
Wouldn't it be nice if it could understand Chef Recipes and Puppet Manifests ?
What if you could create a new environment from Puppet recipe, and injecting it into your Delivery Pipeline.
Eg: I want to create a new delivery stage for exploratory testing and commission an environment that is similar to the one in Production environment. That stage must be placed right after performance testing. I can use that Puppet repository to find the description of such environment that I want.
In an ideal world, one could copy an entire delivery stage, and create a new one, and do the same for environements.
OPEN-SOURCE
No organization wants to be locked in a specific vendor or consulting firm. A CD tool is way too strategic to take that kind of risk.
Open source is what Continuous Delivery experts and all people in Continuous Delivery community want.
Open source is what Continuous Delivery experts and all people in Continuous Delivery community want.
THE PROMISING TOOLS
I will personally monitor Go from Thoughtwork and Legato from CloudSideKick.
Here is a little bit about them:
Here is a little bit about them:
Go has the ability to automate the cycle of build-test-release and providing a single united platform for business people, development team and people in the operations. Go came from Thoughtwork, the same organization whose people coined the term Continuous Development in 2010. Thoughtworks is also the same organization who developed CruiseControl in 2000 that begin the testing automation in Continuous Integration.
Legato is also a CD tool with its cutting edge approach. It is based on the CloudSidekick experience of continuous integration and continuous delivery in their development environment. Therefore it has embodied the soul of automated build-test-release cycle, because CloudSideKick have been working using CI and CD for 15 years. Legato also has the same focus on 3 issues: pushing code through multi-stage pipelines, testing code automatically in virtual environments, and eventually publishing reliable code faster.
Therefore they both will offer some of the above characteristics of the new CD tools.
CONCLUSION
The next generation of CD tool will focus on the delivery pipeline, embrace the cloud and look nice.
In fact the CD tool must document the process itself. In a single view, one must be able to understand the process in place.
In fact the CD tool must document the process itself. In a single view, one must be able to understand the process in place.