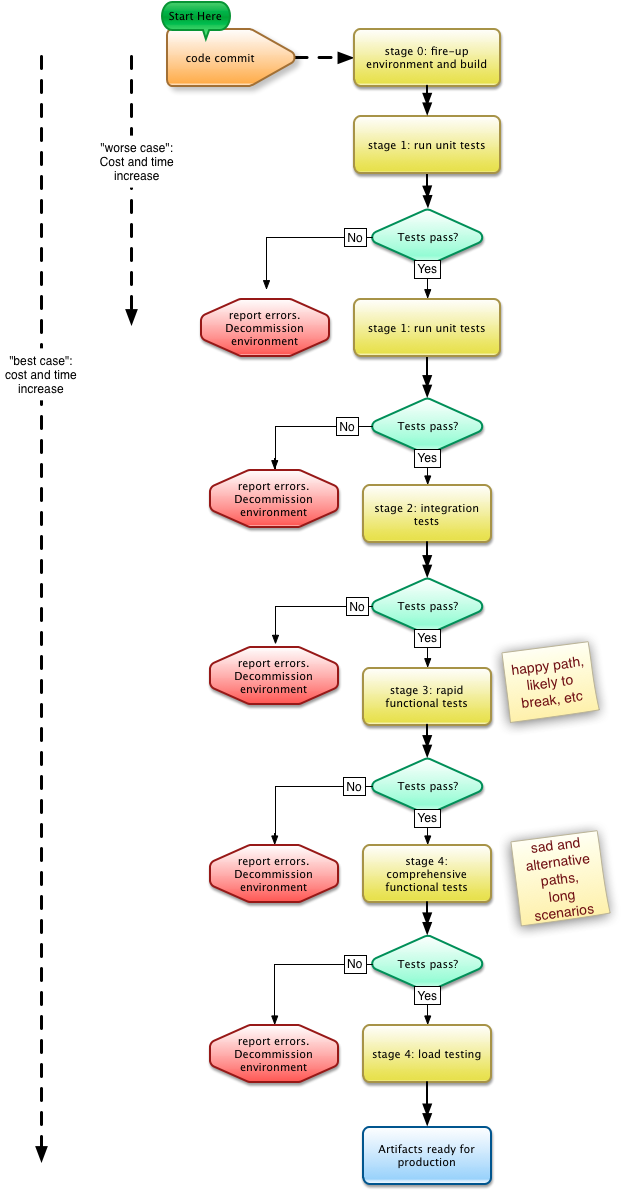
If your software development team has developed some automated functional tests, you might want to enforce a rule to the tests: Do not allow commit the change to the source control repository if any of the functional tests is failing.
This will help isolating the issues and facilitate troubleshooting. One issue is the creation of bottlenecks. Bottlenecks happen when developers cannot commit and are waiting for the build to be fixed.
The solution resides in having one environment per commit:
- Every commit triggers a deployment that runs the whole automated tests suite
- Every code change can be monitored as it is isolated from the others
A continuous integration pipeline should run all the automated tests, including the functional and non-functional tests, whatever the environment (except for the production). There are two issues common with a Continuous Integration pipeline:
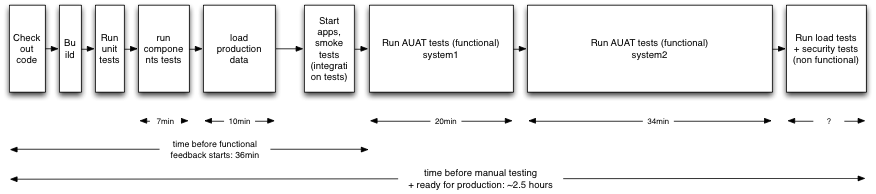
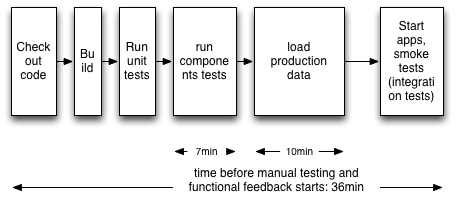
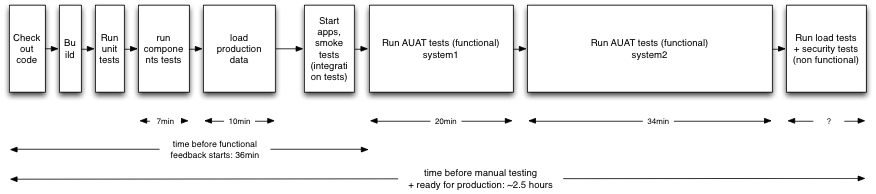
- The automated tests can take up to one or two hours to run and during this time your developers will be waiting a long time for feedback.
- If you have a single environment running all the automated tests and a large team, multiple commits will occur before the tests are run. When the build is broken after the test is done, this multiple commits condition makes it hard to determine which commit broke the build. Therefore we cannot assign who should fix the broken build.
The solution is to use Cloud hosting and create environments on demand!
The ideal situation is to run the full-automated test suite for every commit. This way it’s easy for the developers to take the following actions:
- Revert the last change; and
- Fix the build.
A good rule of thumb is to ask the developer not to commit code if one of the tests is broken. The only exception to this rule is to allow code to be committed which is required to fix a broken test.
A possible issue that can occur is: A bottleneck may occur when there is a broken test that has not been fixed. Consequently, developers are not able to commit the change and testers cannot test the build. For example, if you have 80 developers, probably only 2 of 3 of them are working on the issue and the others will be waiting, wanting to use the automated tests to get feedback on their work.
In order to reduce this bottleneck - can we provide a separate environment for each commit?
- A separate environment for each commit has the following disadvantages: Having 20 or 30 environments running at the same time could be difficult to maintain
- If the team grows you may run out of environments
- Having that many environments may not be cost effective
The current project I'm working on has about 7 servers per environment. In a more complex environment additional servers may be required such as middleware, databases, and application servers.
To solve this problem, we can use environments on demand.
Here are a few tips on how to use Amazon Web Services for environments on demand:
- Always have one or two ‘ready to use’ environments on standby, (servers stopped)
- Create a new environment to run through all the automated tests on each commit
- Ensure that at the end of the pipeline, the artifacts (binaries and other files produced during the build) are stored on an external server or storage space (AWS S3?)
- Shutdown the environment 20 minutes after the automated tests are completed. This gives time for the developer to check the logs and reports and possibly to override the shutdown to keep the environment alive if more investigation is required
- Test results are sent by email or IM to the developer who committed the code
- Keep only 5 last environments and decommission the other ones
Some of the points above will help to minimize costs, but I would bet that implementing environments on demand is not necessarily an expensive solution. The reason is not all developers commit all day long to the central repository because they are in meetings, or discussing design, creating code, prototypes, etc. During those quiet times, not a single environment is running apart from those used for manual testing, UAT or production.
You could ask why the developers do not run all the automated tests on their local development machine? Here are some reasons why it is not always possible:
- A full environment can be too heavy for a laptop
- A testing framework is not always easy to setup
- It might be hard for the developer to keep on working if the automated tests are running at the same time on his machine
In the current project I am working on, we tried to enforce the rule that developers should run all the functional tests on their laptops. Some of them tried and some of them gave up. I could see them relying on our automated test environment and waiting for results. Some of them would even kill the tests as soon as there was an error, so that they could send a quick fix to the central repository and try to run the tests again. This happens when the automated tests need a complex stack of software and they take quite some time to run.
DON'T PUSH, PULL!
In our scenario of on-demand environments, we push the concept of unit tests further. Unit tests are usually meant for quick feedback on the developer's machine, to check whether we have introduced issues with existing code. With environments on demand, every single commit to the central repository is a candidate for production: it has passed all functional and non-functional tests (load tests, integration tests, etc). The binaries are ready to be picked up by the testers or the operation team and put them into production.

Using this approach, you might generate multiple candidates for good builds. You change the process of developers pushing code from one environment to another. Instead, testers can pull the binaries of their choice from the build repository. Most of the time they would pick up a "green" build (not a single test failed, all passed) but sometimes they may decide to take a build that does include some broken tests. After all, it could be a minor bug, not worth fixing or the area they want to test is not related to this bug. This works very well if the test results are readable and easy to understand for a person who is NOT a developer. They must be written in plain English!
COST ISSUE ? RAPID FEEDBACK?
If you worry that building/de-commissioning on-demand environments for every commit is going to be expensive, then ask yourself “how much am I willing to pay to get a build that passes all the tests and is ready for production?” If at the end of the deployment pipeline, you end up with binaries that can be put into production, I bet it was worth paying for the servers during those 2 or 3 hours of intensive automated testing periods.